今後の開発方針
Immutable DDL の改善#
バージョンが増えすぎない工夫#
現在のImmutable DDLの枠組みでは、 ALTER TABLE を発行するたびにバージョン番号が増えていき、かつ古いバージョンのレコードは古いバージョンに入ったままになります。
バージョンの数があまりにも増えると、テーブルの全バージョンを通してどの名前のカラムが存在しているのか、頭の中で管理しきれなくなると予想します。
(かつ、システム的にもパフォーマンスの劣化が激しくなる)
デジタル資料管理において、データに合わせてテーブル構造を気軽に変更していくのは有益と考えますが、あまりにもテーブル構造の種類が多くなってしまうのはかえってデータの管理を煩雑にします。 システムとしてバージョンの数を抑える工夫は重要と考え、以下のような開発を計画しています。
アップグレード#
アップグレードとは、「あるバージョンのレコードを、より大きなバージョンに移す」ことを指します。
例えば v1 から全てのレコードを v2 にアップグレードできたら、 v1 のことは今後気にする必要はありません。
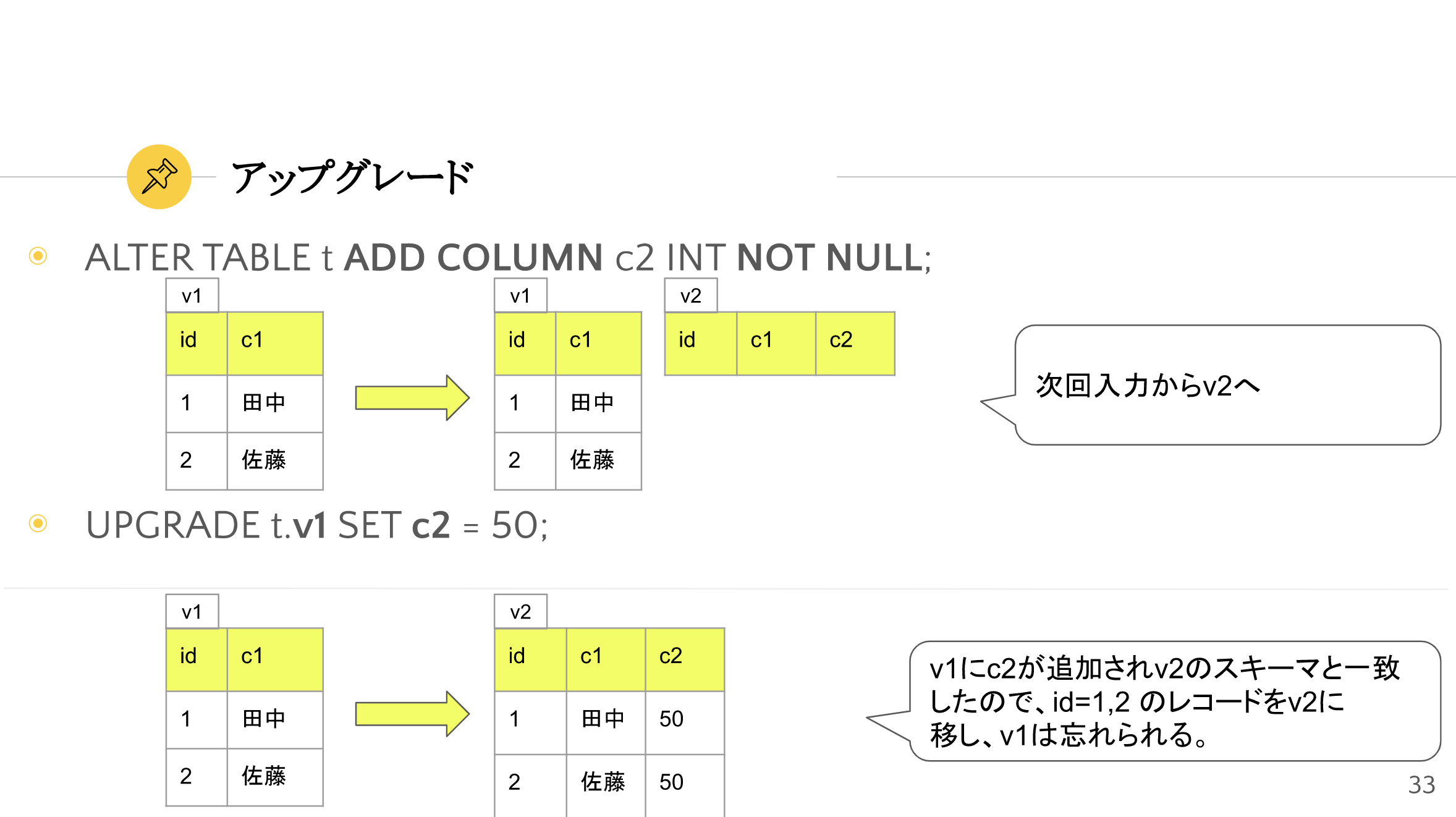
上図においては、 v1 のレコードそのままでは v2 とは構造が合わず (c2 カラムが存在しない) アップグレードできませんが、v2 に移行する際のカラム値を指定することで明示的にアップグレードを実現しています。
アップグレードサジェスト#
ある古いバージョンのレコードを閲覧し、「このカラムの値を埋めればアップグレードできます」のようにサジェストをし、アップグレードを促す機能を検討しています。
自動アップグレード#
特定の状況における ALTER TABLE では、古くなったバージョンのレコードをそのまま新しいバージョンにアップグレードすることができます。
これを自動アップグレードと呼ぶ機能で実現することを検討しています。

古いバージョンへのINSERTに対する警告#
人間が(CMS経由やSQL直打ちで)apllodbに INSERT 文を発行する際は、基本的には最新バージョンのテーブル定義を対象したSQLになることを想定しています。
一方で、データの追加をプログラムなどで自動化している場合には、ALTER TABLE されたことを考慮していない古い形式の INSERT 文が発行され続けることも予想されます。
この状況では、たとえ一時点で古いバージョンからレコードが消えたとしても、古いバージョンへの INSERT が発生した時点で再びレコードが入り、いつまでも古いバージョンのことを考慮する必要が出てきます。
これを避けるために、古いバージョンへの INSERT に対して警告を発する機能を検討しています。
クライアントプログラムが理解できる形式で警告をし、クライアント側のハンドリングに委ねることや、クライアントが望むならエラーとして返却することを検討しています。
DROPしたテーブルの復旧#
Immutable DDLにおいては、 DROP TABLE を発行しても、最新バージョンが deactivated とマークされるだけです。
過去のバージョンのテーブル定義やレコードは全てストレージに残っています。
DROPしたテーブルを復旧する機能を提供することを計画しています。
Immutable DML を有効活用する機能#
UPDATE や DELETE を発行しても、Immutable DML においては、更新・削除前のレコードがリビジョンとして残ります。
デジタル資料管理においては、レコードを修正・削除前に戻したくなることが多いと考え、レコード単位の復旧機能や変更履歴の確認機能を提供することを検討しています。
このようなレコード単位の復旧や履歴閲覧は、通常はアプリケーション層で実現されることが多いですが、デジタル資料管理に特化した apllodb ではデータベース層でこの機能を実現することに意義があると考えます。
RDBMSとしての基礎力向上#
apllodb v0.1 には以下のような制限があります。
- 使用できるSQLの文が少ない。
- 利用できるデータ型の種類が少ない。
- プライマリキーの値を更新できない。
この他にも、通常のRDBMSにはできてapllodbにはできないことが数多くあり、大きな改善対象です。
デジタル資料管理のための新機能#
範囲が曖昧なデータの挿入・検索#
デジタル化の対象となる資料が歴史的な対象を扱う場合、曖昧なデータが多く登場すると考えられます。
- 生年: 1200年から1230年頃
- 規模: 1000人から10000万人
この種のデータをRDBMSで管理する際に、上限値や下限値をカラムに設定することも一般的に考えられるアプローチですが、例えば確率分布を導入し、中央値と分散を管理することも検討の余地があると考えます。
この考えが実用上有益ならば、apllodbで実現する可能性があります。