Future Development Plan
Improve Immutable DDL#
Keep small number of versions#
In the current framework of Immutable DDL, each time you issue ALTER TABLE, the version number increases, and yet the records in the older version remain in the older version.
If the number of versions increases too much, we expect that we will not be able to keep track of which named columns are present in all versions of the table.
(And, systemically, there will be severe performance degradation.
In digital document management, it is beneficial to casually change the table structure according to the data, but too many different table structures will make data management more complicated. We believe that it is important to limit the number of versions of the system, and we are planning to develop the following.
Upgrade#
Upgrading means "moving records from one version to a larger version".
For example, if you can upgrade all records from v1 to v2, you don't need to worry about v1 in the future.
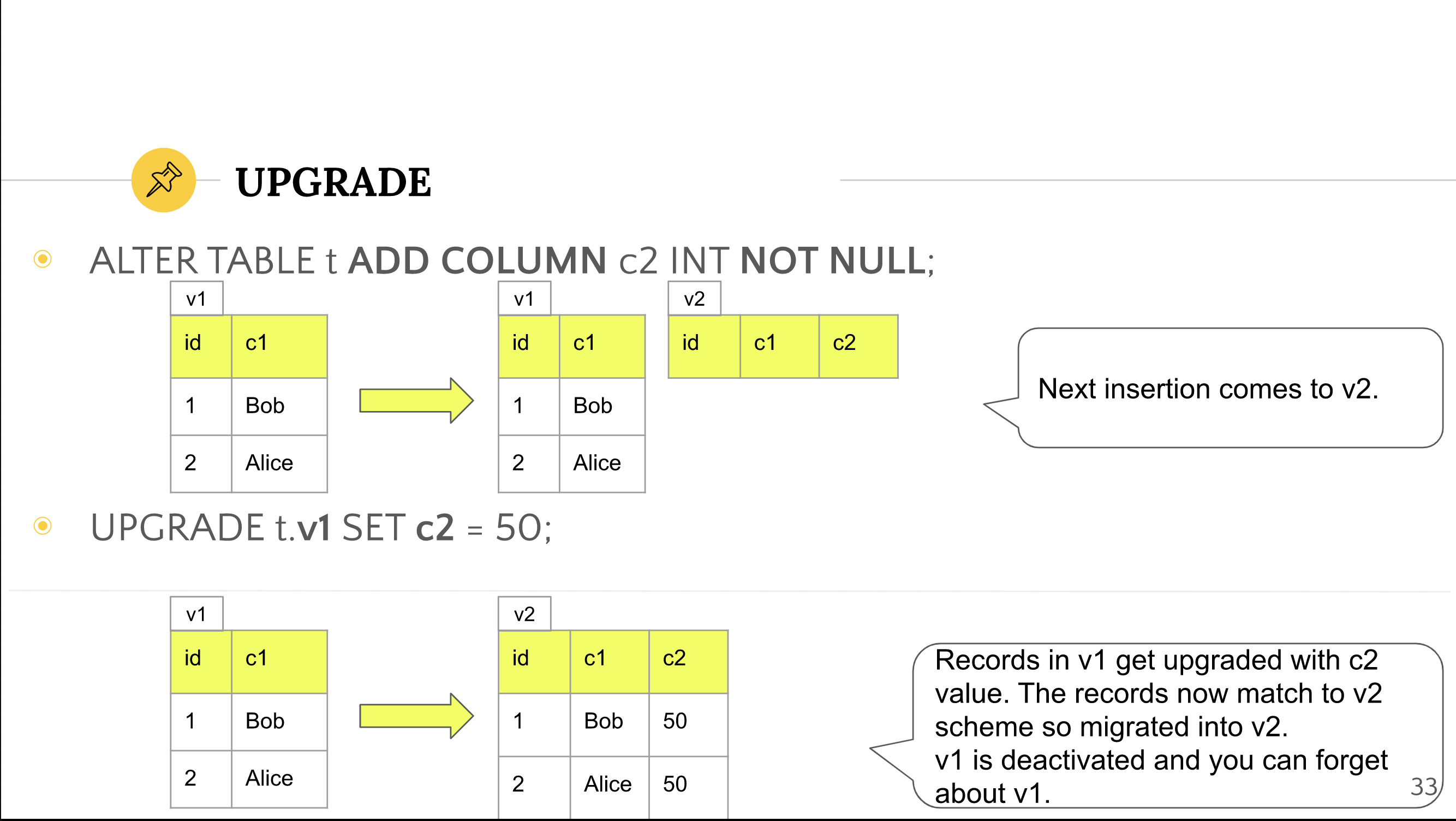
In the above figure, the structure of the v1 record does not match that of v2 (the c2 column does not exist), so it cannot be upgraded, but the upgrade is explicitly achieved by specifying the column values to be used when migrating to v2.
Upgrade suggestion#
We are considering a function that will browse records of a certain old version and give suggestions like "You can upgrade by filling in the values in this column" to encourage upgrading.
Auto-upgrade#
In certain situations ALTER TABLE can upgrade records from an outdated version to a newer version without modification.
We are looking at doing this with a feature we call automatic upgrade.

Warnings to INSERT into old versions#
When a human being issues an INSERT statement to apllodb (via CMS or direct SQL), it is basically assumed that the SQL will be for the latest version of the table definition.
On the other hand, if adding data is automated programmatically, it is expected that INSERT statements that do not take ALTER TABLE into account will continue to be issued.
In this situation, even if records are lost from the old version at some point, they will be reintroduced when an INSERT to the old version occurs, and the old version will need to be taken into account forever.
To avoid this, we are considering a feature to issue a warning for INSERT to an older version.
We are considering giving the warning in a format that the client program can understand, and leaving it to the client to handle, or returning it as an error if the client wishes.
Restoring DROP-ed tables#
In Immutable DDL, issuing a DROP TABLE will only mark the latest version as deactivated.
All table definitions and records from previous versions are still in storage.
We are planning to provide a feature to recover DROP-ed tables.
Better utilize Immutable DML#
Even if you issue UPDATE or DELETE, the record before the update or deletion remains as a revision in Immutable DML.
We believe that in digital document management, we often want to restore records to the way they were before they were modified or deleted, so we are considering providing record-by-record recovery and change history viewing functions.
We are considering to provide a function to recover each record and to check the change history. Such functions are usually implemented in the application layer, but in apllodb, which specializes in digital document management, we think it is meaningful to implement such functions in the database layer.
Improve RDBMS basics#
apllodb v0.1 has the following limitations.
- Fewer SQL statements are available.
- Fewer data types are available.
- Cannot update the value of the primary key.
There are many other things that apllodb can do that normal RDBMSs can't, which is a big improvement.
New features for digital document management#
Insertion and retrieval of data with ambiguous scope#
When the materials to be digitized deal with historical objects, it is expected that many ambiguous data will appear.
- Year of birth: around 1200 to 1230
- Size: 10 to 10 million people
When managing this kind of data in an RDBMS, setting upper and lower limits in columns is a common approach, but I think there is room for consideration in introducing probability distributions, for example, and managing medians and variances.
If this idea is practically useful, it could be implemented in apllodb.