Immutable Schema
As described in Introduction, Immutable Schema consists of Immutable DDL and Immutable DML. Immutable Schema enables the organization of new information obtained through observation of data for digital material management without destroying existing data (records).
This chapter describes the specifications of Immutable DDL and Immutable DML, and some implementation details in v0.1.
Immutable DDL Overview#
In DDL of a normal RDBMS, table definitions created with the CREATE TABLE statement can be modified with the ALTER TABLE statement or dropped with the DROP TABLE statement.
If a table definition is modified (dropped) with ALTER TABLE or DROP TABLE, the original table definition cannot be recovered.
Immutable DDL makes this possible. In Immutable DDL, a table has versions.
CREATE TABLE t ...createsv1of tablet.- Then
ALTER TABLE t ...createsv2of tablet. The table definition ofv1and the records insidev1will remain unchanged. - Then
DROP TABLE twill createv3of tabletas in deactivated state. Sincev3is in deactivated state, any operation ontwill fail basically. The records associated withv1andv2remain intact.
The behavior in the case of ALTER TABLE is illustrated below.

Quoted from "Introduction to apllodb" slides.
ADD COLUMN adding a NOT NULL column without any default value is not possible in a normal RDBMS because it doesn't know what value to set to the new column of an existing record.
With Immutable DDL, v2 is created without error. Table definition before adding the column remains as v1 and records are kept in v1.
Next INSERT will be directed to v2 if the value is also set for the added column.
Next, let's look at an example of DROP COLUMN.
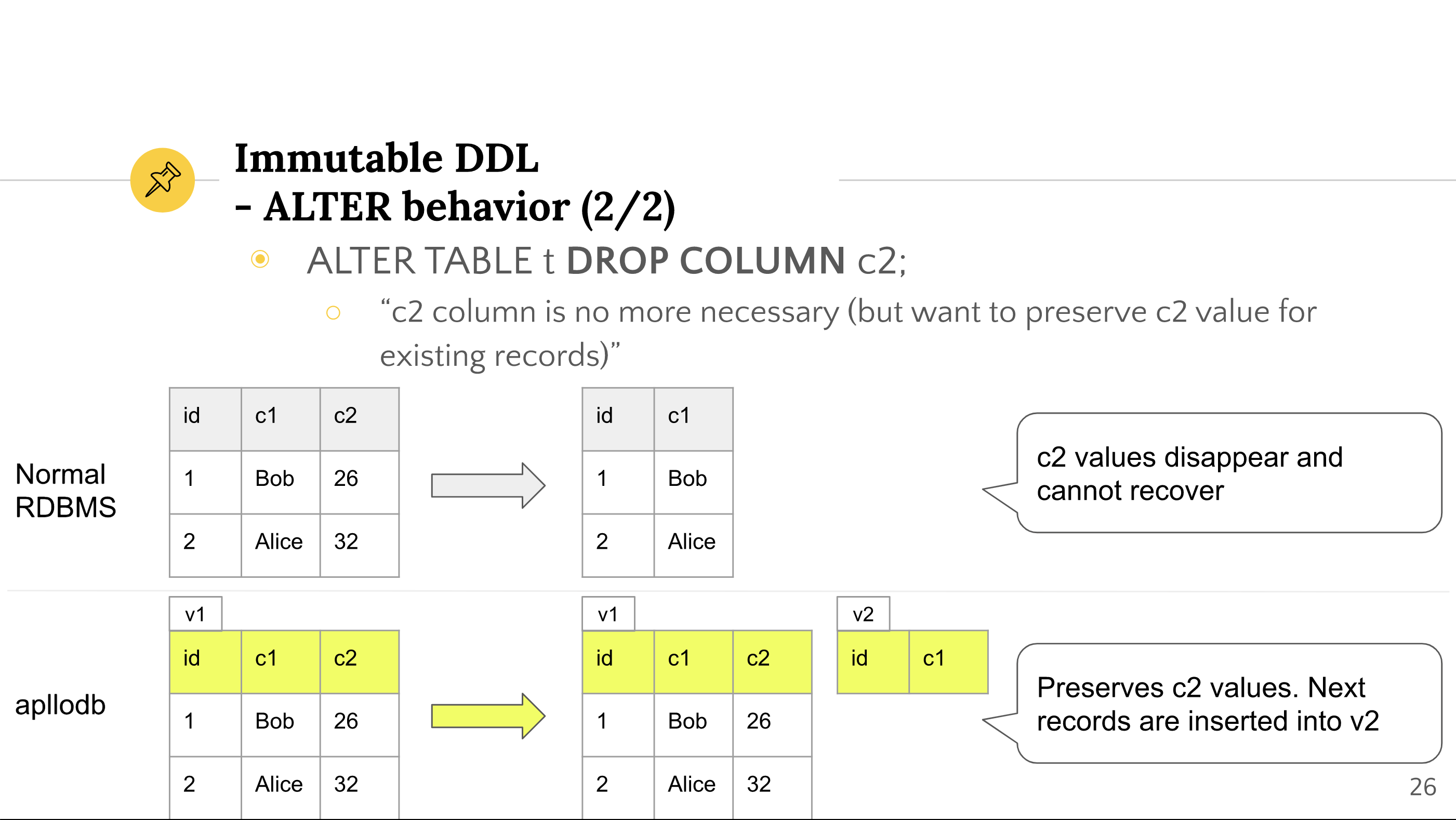
Quoted from "Introduction to apllodb" slides.
In a normal RDBMS, column values will also disappear from existing records. There is nothing wrong with this behavior, but in the case of digital document management, there may be a case where you don't want to fill this column anymore, but want to keep the column values you have filled so far.
In this case, Immutable DDL can be useful. Even if you delete a column from a table definition, the table definition and records before the column deletion will remain in v1.
So far, we have explained that issuing DDL creates a new version in the table definition, and the records are still associated with old versions.
In the next section, we will explain how DML such as SELECT and INSERT behaves in a situation where multiple versions exist.
Details of Immutable DDL.#
SELECT behavior#
When the SELECT target table is t, all versions (not deactivated via DROP TABLE) will be processed according to the following rules.
- (Rule 1) Error if the column
cin theSELECTstatement does not exist in any version oft. - (Rule 2) If
cexists in some version oft, records in that version return the column value forc. - (Rule 3) If
ccolumn does not exist in some version, records of that version return NULL value forc.
Let's explain with an example.
Consider the following three versions and records are in table t.
v3| c1 | c2 ||----|----|| 1 | 10 |
v2| c1 | c2 | c3 ||----|----|----|| 3 | 30 | 33 |
v1| c1 ||----|| 2 |At this time, the
SELECT c4 FROM t;will result in an error according to rule 1 (the column c4 does not exist).
Let's look at some other examples.
SELECT c1 FROM t;
-- result (in undefined order)| c1 ||----|| 1 || 3 || 2 |Rule 2 is applied.
SELECT c1, c2, c3 FROM t;
-- result (undefined order)| c1 | c2 | c3 ||----|------|------|| 1 | 10 | NULL || 3 | 30 | 33 || 2 | NULL | NULL |Rules 2 and 3 are applied.
So far, we've learned Projection (specifying the columns to fetch immediately after the SELECT), let's look at
WHEREGROUP BYORDER BYJOIN
The same rules apply to the columns that appear in the above clauses. By rule 3, NULL may appear but these operations have defined behavior as SQL standard when NULL appears1, and return the result according to that specifications.
SELECT c1, c2, c3 FROM t WHERE c2 > 15;
-- result| c1 | c2 | c3 ||----|------|------|| 3 | 30 | 33 |SELECT c1, c2, c3 FROM t ORDER BY c2 DESC;
-- result (NULL is subordinate to any value)| c1 | c2 | c3 ||----|------|------|| 3 | 30 | 33 || 1 | 10 | NULL || 2 | NULL | NULL |1 GROUP BY nullable_column, for example, have different default behavior depending on RDBMS implementations. apllodb v0.1 adopts PostgreSQL compliant semantics.
INSERT behavior#
When the table to be INSERTed is t, all versions (not deactivated by DROP TABLE) will be processed according to the following rules.
- (Rule 1) Iterate versions in descending order, and attempt to insert a record into a version if an insert with an
INSERTstatement can be performed successfully for that version.- (Rule 1.1) Error if a table-wide constraint is violated.
- (Rule 1.2) Otherwise, insert into that version completes successfully.
- (Rule 2) If rule 1 does not work for one version, choose a smaller version and repeat.
- (Rule 3) If the insertion into
v1does not complete successfully, the execution of theINSERTstatement will fail.
Let's explain with an example.
Consider the case where the table t has the following three versions and a table-wide constraint
- v3
c1: NOT NULLc2: NOT NULL
- v2
c1: NOT NULLc2: NOT NULLc3: NULL
- v1
c1: NOT NULL
- Table-wide constraints
id: PRIMARY KEY
Let's look at a few INSERT statements and their results.
INSERT INTO t (c1, c2) VALUES (1, 10);Following rule 1, apllodb will first try to insert into v3. Insertion into v3 is OK, so rule 1.2 will complete the INSERT statement successfully.
(Inserting into v2 is also possible, but v2 will not be selected, since the INSERT candidates are ordered by descending version.
INSERT INTO t (c1, c2, c3) VALUES (3, 30, 33);Following rule 1, apllodb first try to insert into v3. Since v3 does not have a column named c3, apllodb move to rule 2, and then back to rule 1 with an attempt on v2.
Inserting into v2 is OK, so rule 1.2 will complete the INSERT statement successfully.
INSERT INTO t (c1) VALUES (2);Both v3 and v2 will fail because they require c2. v1 completes successfully.
INSERT INTO t (c4) VALUES (4);Since none of v3, v2, or v1 has c4, rule 3 causes this INSERT statement to fail.
INSERT INTO t (c1, c2, c3) VALUES (1, 100, 111);v3 does not have c3, so it tries to insert into v2.
Since the record with c1 = 1 already exists, it violates the table-wide constraint c1 PRIMARY KEY. Therefore, according to rule 1.1, this INSERT statement will result in an error.
Immutable DML Overview#
In a normal RDBMS DML, a record created with an INSERT statement can be updated with an UPDATE statement or deleted with a DELETE statement.
If a record is updated (deleted) by UPDATE or DELETE, the original record cannot be recovered 2.
Immutable DML allows records to have revision and to be restored to a previous revision.
- A table always has a primary key, and the primary key is the same for all versions.
- There is a one-to-many association between primary keys and revisions.
- The first time the value of a primary key is created by an
INSERTstatement, the record will be in ther1revision. - When the record of the primary key is updated by an
UPDATEstatement, the record ofr1remains unchanged, and the record ofr2is created (internally, theINSERTprocess runs). - When a record with the same primary key is deleted by a
DELETEstatement, the record ofr3is created with only a delete mark and no content. - In
SELECT, only the latest revision of the same primary key is retrieved. If the latest revision has a delete mark, the record of the primary key will not be retrieved.
Here is an illustration of the behavior in the case of UPDATE.

Quoted from "Introduction to apllodb" slide.
In a normal RDBMS, the value of c1 is overwritten by UPDATE and cannot usually be restored to its original value 3.
In digital document management, we believe that we often want to revert records they were before modified or deleted.
In Immutable DML, past records remain in the form of revisions, which can be recovered if necessary. It is also possible to extract the change history of a record.
2 Some RDBMSs have destructive DMLs like UPDATE and DELETE in append-manner like Immutable DML. Many of them perform garbage collection at some point (background processing, VACUUM command, etc.) to complete destructive DML. The aim is to reduce capacity and improve performance.
3 Possible if you have snapshot backups but we don't think many systems support record-by-record recovery.
Immutable DDL and Immutable DML implementations#
apllodb v0.1 uses SQLite for table structure and record storage (and transaction). Immutable DDL and Immutable DML are also implemented over SQLite.
In this section, we will explain how to realize Immutable Schema based on existing RDBMS.

We will set up tables as shown in the above figure in the existing RDBMS.
The layer with blue background is the real tables that need to be created for one table T in Immutable Schema.
The figure above shows a setup where table T has two versions, v1 and v2.
The role of each table is as follows
- Physical tables for all apllodb's tables
_vtable_metadata.- Manages the metadata for the table.
- Currently, constraints table-wide constraints (PRIMARY KEY, UNIQUE) for metadata.
- Manages the metadata for the table.
_version_metadata.- Manage metadata for each version.
- Version number
- Name and data type of each column.
- Constraints to check one record at a time (NOT NULL, DEFAULT, CHECK, ...)
- Active version (not being
DROP TABLEed)
- Manage metadata for each version.
- Real table for table `T
T__navi.- A relay table for locating the entity of a record with a primary key.
- Also supports composite primary keys.
- It has a revision number, and "the latest revision with a primary key value" is found in this table.
- It has a version number and can be used to join non-primary key column values with the
T__v?table.
- A relay table for locating the entity of a record with a primary key.
T__v?.- holds the records (non-primary key columns) of version
v?.
- holds the records (non-primary key columns) of version
See README of the storage engine for details of columns in the real table.
Here is an overview of how these tables are referenced in a SELECT statement.
Full scan case#
- Browse the
T__navitable and extract the record with the highest revision number for each primary key value. - Get the non-primary key column values of those records by joining them with the
T__v?table.
Exact match search by primary key#
- Refer to the
T__navitable, do a match search for the primary key value, and extract the record with the highest revision number. - Get the non-primary key column value of the record by joining it with the
T__v?table.
Range search by primary key#
- Refer to the
T__navitable, do a range search for the primary key value, and extract the record with the highest revision number. - Get the non-primary key column value of the record by joining it with the
T__v?table.
Exact match search and range search by non-primary key.#
Indexes on non-primary keys are not supported in apllodb v0.1. Current apllodb performs performs full scan and then filter-out record that do not match the search criteria.
When we support indexing, we envision that the primary key can be subtracted from the index and from there it can be dropped into the "For match search by primary key".