Immutable Schema
イントロダクション で述べたように、Immutable SchemaはImmutable DDLとImmutable DMLから成ります。 Immutable Schemaは、デジタル資料管理のために既に追加したデータ(レコード)を破壊せず、データの観察により得られた新たな情報の整理を可能にします。
この章ではImmutable DDLとImmutable DMLの仕様と、v0.1 における実装手法について説明します。
Immutable DDLの概要#
通常のRDBMSのDDLでは、 CREATE TABLE 文で作成したテーブル定義を ALTER TABLE 文で修正したり、 DROP TABLE 文で削除したりすることができます。
ALTER TABLE や DROP TABLE でテーブル定義が変更(削除)されると、元のテーブル定義は復旧できません。
これを可能にするのがImmutable DDLです。 Immutable DDLにおいては、テーブルが バージョン を持ちます。
CREATE TABLE t ...により、テーブルtのv1が作成される。- 続いて
ALTER TABLE t ...をすると、テーブルtのv2が作成される。v1のテーブル定義とv1に紐づくレコードは、そのまま残る。 - 続いて
DROP TABLE tをすると、テーブルtのv3が作成される。v3は deactivated 状態であり、tに対する操作は原則エラーになる。v1,v2に紐づくレコードはそのまま残っている。
ALTER TABLE の場合の挙動を図解します。

『apllodbの構想』スライドより引用
まずは ADD COLUMN ですが、デフォルト値がなく、かつ NOT NULL であるカラム追加は、通常のRDBMSではできません。
既存レコードの新しいカラムにセットすべき値が決まらないためです。
Immutable DDLでは、カラム追加前のテーブル定義が v1 として残り、レコードも v1 に紐付いて保持されるため、エラーなく v2 ができます。
次回以降のINSERTは、追加カラムに対しても値をセットしていれば、 v2 に向きます。
続いて DROP COLUMN の例を見ます。
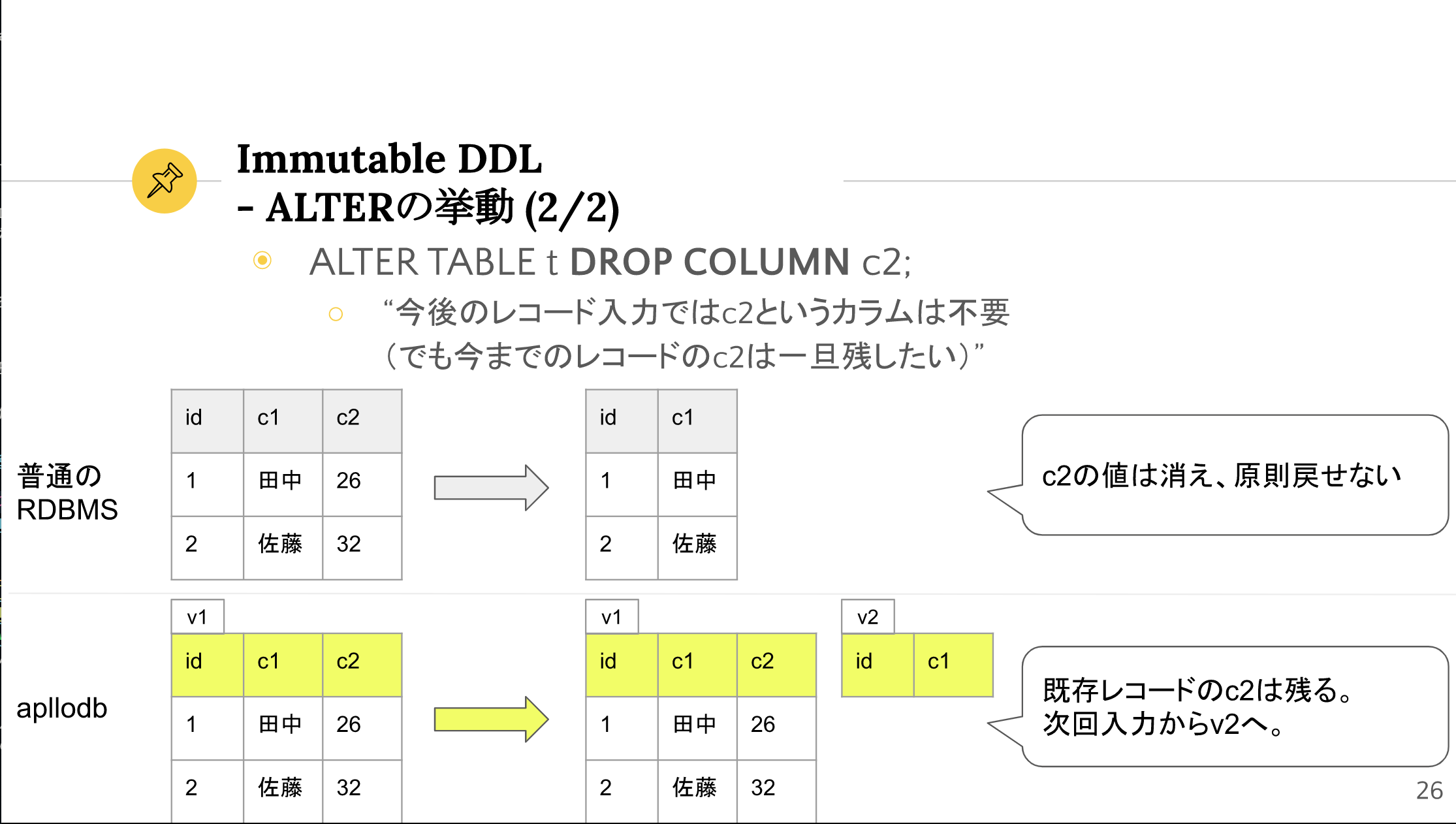
『apllodbの構想』スライドより引用
通常のRDBMSでは、既存レコードからカラムの値も消えてしまいます。
これは何らおかしい挙動ではないのですが、デジタル資料管理においては「今後はこのカラムもう入力しないで良いけど、今まで入力したカラム値はせっかくだから残していたい」というケースがあると考えます。
その場合にもImmutable DDLは役立ちます。カラムをテーブル定義から削除しても、 v1 にはカラム削除前のテーブル定義とレコードがそのまま残るからです。
ここまでで、DDLを発行するとテーブル定義の中にバージョンができあがり、レコードも古いバージョンに紐づく形でそのまま残ることを説明しました。
次の節では、複数のバージョンが存在する状況で、 SELECT や INSERT などのDMLがどのような挙動となるかを説明します。
Immutable DDLの詳細#
SELECT時の挙動#
SELECT 対象のテーブルが t の場合、(DROP TABLE により deactivated にされていない) 全バージョンについて、以下のルールに従い処理が行われます。
- (ルール1)
SELECT文において要求されているテーブルtのカラムcが、tのいずれのバージョンにも存在していなければエラー。 - (ルール2)
tのcがあるバージョンには存在している場合、そのバージョンのレコードはcについてカラム値を返す。 - (ルール3)
tのcがあるバージョンには存在していない場合、そのバージョンのレコードはcについてNULL値を返す。
例を挙げて解説します。
テーブル t に、以下の3つのバージョンとレコードが存在する場合を考えます。
v3| c1 | c2 ||----|----|| 1 | 10 |
v2| c1 | c2 | c3 ||----|----|----|| 3 | 30 | 33 |
v1| c1 ||----|| 2 |この時、
SELECT c4 FROM t;は、ルール1によりエラーとなります (c4 というカラムは存在しない)。
他の例も見てみましょう。
SELECT c1 FROM t;
-- 結果 (順序は不定)| c1 ||----|| 1 || 3 || 2 |ルール2が適用されています。
SELECT c1, c2, c3 FROM t;
-- 結果 (順序は不定)| c1 | c2 | c3 ||----|------|------|| 1 | 10 | NULL || 3 | 30 | 33 || 2 | NULL | NULL |ルール2とルール3が適用されています。
ここまで Projection (結果として取得するカラムの絞込み指定。 SELECT c1, c2 FROM ... の c1, c2 の部分) について見ましたが、
WHEREGROUP BYORDER BYJOIN
に現れるカラム指定についても同じルールが適用されます。 ルール3によってNULLが現れることがありますが、これらの演算には値としてNULLが現れた場合の挙動がSQL標準として定義されており1、その挙動に従って結果を返します。
SELECT c1, c2, c3 FROM t WHERE c2 > 15;
-- 結果 (NULLが現れる式は全てFALSE判定される)| c1 | c2 | c3 ||----|------|------|| 3 | 30 | 33 |SELECT c1, c2, c3 FROM t ORDER BY c2 DESC;
-- 結果 (NULLはどの値よりもソート順が劣後)| c1 | c2 | c3 ||----|------|------|| 3 | 30 | 33 || 1 | 10 | NULL || 2 | NULL | NULL |1 GROUP BY nullable_column などは、RDBMS処理系によってデフォルトの挙動が異なる状況ですが、apllodb v0.1 ではPostgreSQL準拠の意味論を採用しています。
INSERT時の挙動#
INSERT 対象のテーブルが t の場合、(DROP TABLE により deactivated にされていない) 全バージョンについて、以下のルールに従い処理が行われます。
- (ルール1) バージョンを降順に見て、
INSERT文による挿入がそのバージョンについて正常に実行し得るならば、そのバージョンへのレコード挿入を試みる。- (ルール1.1) テーブル全体の制約に違反した場合はエラー。
- (ルール1.2) さもなくばそのバージョンへの挿入が正常に完了。
- (ルール2) ルール1であるバージョンについて正常に実行できなければ、より小さいバージョンを選び繰り返す。
- (ルール3)
v1への挿入も正常に完了しなかった場合、INSERT文の実行がエラーとなる。
例を挙げて解説します。
テーブル t に、以下の3つのバージョンと、テーブル全体の制約が存在する場合を考えます。
- v3
c1: NOT NULLc2: NOT NULL
- v2
c1: NOT NULLc2: NOT NULLc3: NULL
- v1
c1: NOT NULL
- テーブル全体の制約
id: PRIMARY KEY
この場合にいくつかの INSERT 文とその結果を見てみます。
INSERT INTO t (c1, c2) VALUES (1, 10);ルール1に従い、まず v3 への挿入を試みます。v3 への挿入は問題なくできるので、ルール1.2によりINSERT文は正常完了します。
(v2 への挿入も可能ですが、バージョンの大きい順から挿入候補となるので、 v2 は選ばれません。)
INSERT INTO t (c1, c2, c3) VALUES (3, 30, 33);ルール1に従い、まず v3 への挿入を試みます。v3 には c3 というカラムがないので、ルール2へ移行し、v2 を試みる形でルール1へ戻ります。
v2 への挿入は問題なくできるので、ルール1.2によりINSERT文は正常完了します。
INSERT INTO t (c1) VALUES (2);v3, v2 ともに c2 を要求するため、失敗します。v1 へ至り正常完了します。
INSERT INTO t (c4) VALUES (4);v3, v2, v1 のいずれも c4 を持たないので、ルール3により、このINSERT文はエラーとなります。
INSERT INTO t (c1, c2, c3) VALUES (1, 100, 111);v3 は c3 を持たないので v2 への挿入を試みます。
c1 = 1 であるレコードは既に存在するので、テーブル全体の制約である c1 PRIMARY KEY に違反します。従ってルール1.1により、このINSERT文はエラーとなります。
Immutable DMLの概要#
通常のRDBMSのDMLでは、 INSERT 文で作成したレコードを UPDATE 文で更新したり、 DELETE 文で削除したりすることができます。
UPDATE や DELETE でレコードが更新(削除)されると、元のレコードは復旧できません2。
Immutable DMLでは、レコードが リビジョン を持ち、以前のリビジョンへの復旧を可能にします。
- テーブルは必ずプライマリキーを持ち、プライマリキーはどのバージョンも共通。
- プライマリキーとリビジョンは1対多対応。つまり、同一のプライマリキーを持つリビジョンが1つ以上存在する。
- あるプライマリキーの値が
INSERT文により初めて現れた時、そのレコードはr1のリビジョンになる。 - そのプライマリキーのレコードが
UPDATE文により更新された時、r1のレコードはそのまま残り、r2のレコードが追記の形で(内部的にはINSERT処理が走る形で)作成される。 - 同じプライマリキーのレコードが
DELETE文により削除された時、r3のレコードが、削除マークのみで中身はない形で作成される。 SELECTにおいては、同じプライマリキーの中の最新リビジョンのみが取得される。最新リビジョンに削除マークが付いていたら、そのプライマリキーのレコードは取得対象にならない。
UPDATE の場合の挙動を図解します。
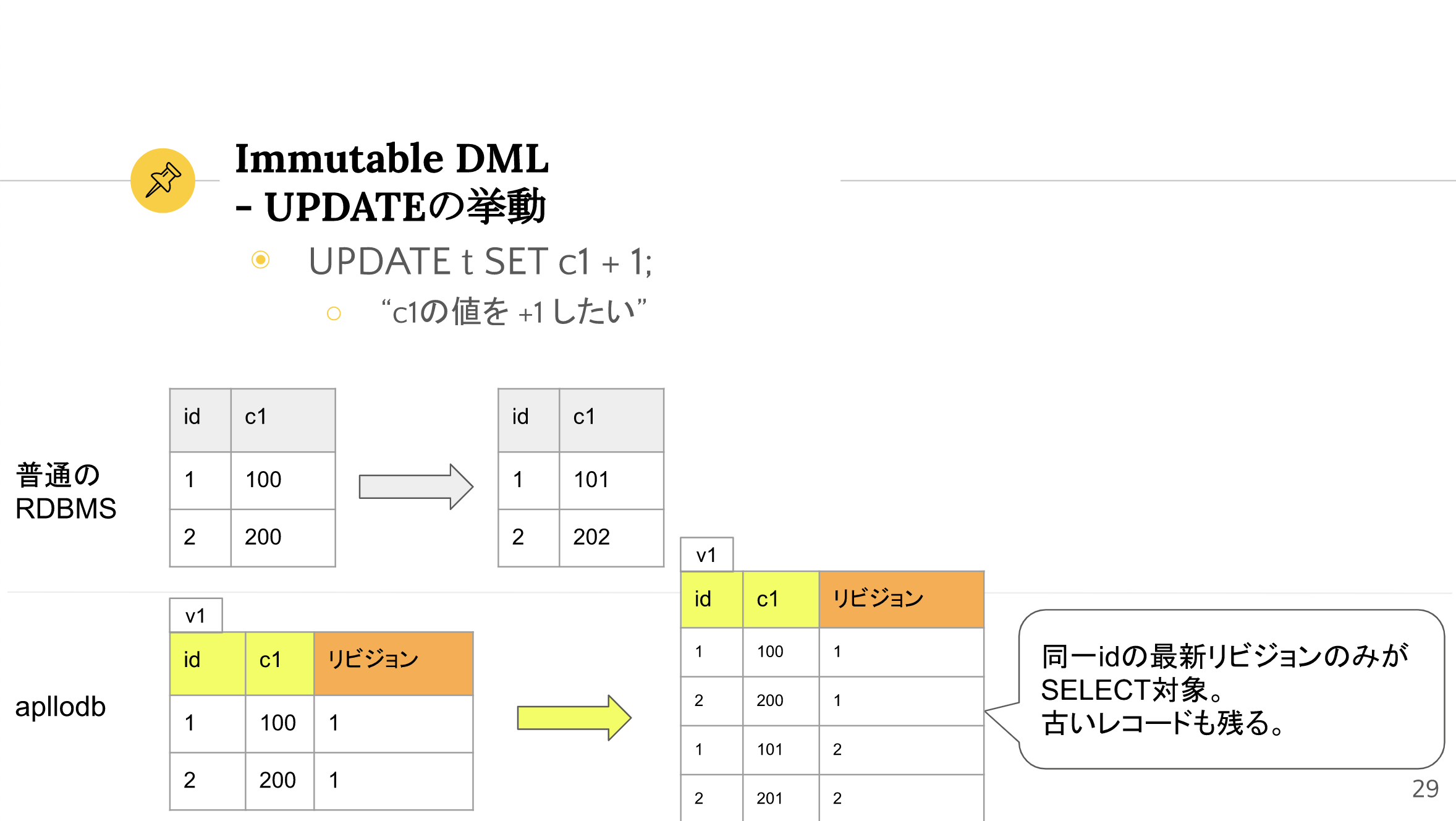
『apllodbの構想』スライドより引用
通常のRDBMSでは、c1 の値が UPDATE で上書きされるため、通常元の値に戻すことはできません3。
デジタル資料管理においては、レコードを修正・削除前に戻したくなることが多いと考えます。
Immutable DMLでは、過去のレコードもリビジョンの形で残っているため、必要に応じて復旧することが可能です。また、あるレコードの変更履歴を抽出することも可能です。
2 一部のRDBMSでは、UPDATEやDELETEのような破壊的なDMLを、Immutable DMLのように追記型で行っています。そのうちの多くは、何かのタイミング(バックグラウンド処理や VACUUM コマンドなど)でガーベージコレクションを実行し、破壊的なDMLを完了させます。容量削減やパフォーマンス向上の狙いがあります。
3 スナップショットのバックアップがある場合などは可能ですが、レコードごとの復旧をサポートしているシステムはあまりないかと思います。
Immutable DDL, Immutable DMLの実装手法#
apllodb の v0.1 は、テーブル構造やレコードの保存(並びにトランザクションの実装)に SQLite を使用しています。 Immutable DDLやImmutable DMLも、SQLiteの上で実装しています。
この節では、既存のRDBMSをベースにImmutable Schemaを実装するための手法を説明します。

上図のようなテーブルを、既存のRDBMSに設けます。
青色背景のレイヤー部分は、Immutable Schemaにおけるテーブル T 一つについて作る必要のある実テーブル群です。
上図は、テーブル T は2つのバージョン v1 と v2 を持つ設定です。
各テーブルの役割は次のとおりです。
- 全テーブルまたいだ実テーブル
_vtable_metadata- テーブルのメタデータを管理。
- 現在は、テーブル全体の制約 (PRIMARY KEY, UNIQUE) をメタデータとしている。
- テーブルのメタデータを管理。
_version_metadata- バージョンごとのメタデータを管理。
- バージョン番号
- 各カラムの名前・データ型
- 1レコードずつ確認できる制約 (NOT NULL, DEFAULT, CHECK, ...)
- activeなバージョンか (DROP TABLE されていないか)
- バージョンごとのメタデータを管理。
- テーブル
Tに関する実テーブルT__navi- プライマリキーをキーとし、レコードの実体を探すための中継テーブル。
- 複合プライマリキーにも対応。
- リビジョン番号を持ち、このテーブル内で「あるプライマリキー値を持つ最新のリビジョン」が判明する。
- バージョン番号を持ち、非プライマリキーのカラム値を
T__v?テーブルと結合しにいける。
- プライマリキーをキーとし、レコードの実体を探すための中継テーブル。
T__v?- バージョン
v?のレコード(の非プライマリキーカラム)を保持。
- バージョン
実テーブルのカラムの詳細は ストレージエンジンのREADME を参照してください。
SELECT 文において、これらのテーブルがどのように参照されるかを概説します。
フルスキャンの場合#
T__naviテーブルを参照し、各プライマリキー値について、最もリビジョン番号が高いレコードを抽出。- そのレコードの非プライマリキーカラム値を
T__v?テーブルと結合して取得。
プライマリキーによる一致検索の場合#
T__naviテーブルを参照し、プライマリキー値について一致検索し、最もリビジョン番号が高いレコードを抽出。- そのレコードの非プライマリキーカラム値を
T__v?テーブルと結合して取得。
プライマリキーによる範囲検索の場合#
T__naviテーブルを参照し、プライマリキー値について範囲検索し、最もリビジョン番号が高いレコードを抽出。- そのレコードの非プライマリキーカラム値を
T__v?テーブルと結合して取得。
非プライマリキーによる一致検索・範囲検索の場合#
非プライマリキーに対するインデックスは apllodb v0.1 ではサポートされておらず、フルスキャンを実行した後に、検索条件に合致しないレコードを除外しています。
インデックスをサポートする際は、インデックスからプライマリキーが引け、そこからは「プライマリキーによる一致検索の場合」に落とし込めると構想しています。